[Paper Review] Domain adapted broiler density map estimation using negative-patch data augmentation
논문 list는 이 repo에 정리되어있습니다.
Domain adapted broiler density map estimation using negative-patch data augmentation
Taehyeong Kim, Dae-Hyun Lee, Wan-Soo Kim, Byoung-Tak Zhang, Domain adapted broiler density map estimation using negative-patch data augmentation,Biosystems Engineering,Volume 231,2023,Pages 165-177,ISSN 1537-5110
1. Introduction
인구 증가 및 소득 증가의 영향으로 닭고기의 수요와 소비량은 꾸준히 증가함.
생산의 효율성을 위해 자유방목보다 폐쇄형으로 사육이 선호됨.
그에 따라 닭 사육은 높은 밀도로 사육됨.
높은 밀도로 사육됨에 따라, 행동이 제한돼 체온, 스트레스, 공포가 증가.
이에 따른 닭 품질 저하.
따라서 축산업계에서는 동물 복지 등을 통해 축산 품질 향상을 도모함.
해결하기 위한 사육 밀도를 관리하기 위해 사육 환경을 지속적으로 모니터링할 필요가 있음. 같은 수의 육계더라도, 사육환경과 성장 상태에 따라 밀도가 달라질 수 있음.
육계를 자동적으로 관찰하기위해 이전 연구들
- 사육 방법별 6가지 파라미터를 이용한 육계 행동 평가
- 사육 밀도에 따른 페킨 오리의 성장 및 활동 모니터링
- 육계 복지 평가를 돕기 위한 백색 육계의 행동 분류
- 중심체 분할 기반 동적 모델링을 이용한 체중 예측
그러나 이 연구들은 수만 마리 육계같은 혼잡한 무리의 모니터링에는 문제가 있음
자동으로 관찰하기 위해서는 고밀도 무리를 효과적으로 선별할 수 있는 기술이 필요함
딥러닝을 통해 물체를 자동으로 감지하는 솔류션이 많은 분야에서 적용됨
-
CNN : 이미지 객체분류, 감지, 분할에 강력
- 다양한 CNN 기반 아키텍쳐에 따라 사람, 사람 밀도를 평가하는데 사용되는 군중 수 계산 방법에 사용
- 대규모 이벤트를 모니터링하여 군중 재난을 예방하는데 적용 –> 성공적인 밀도 맵 추정 & end to end learning : 뛰어난 성능
end to end learning : 입력에서 출력까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리한다는 의미
-
Density based counting method는 최근(2019)년에 양돈장의 돼지 수를 세는데 적용 <- 대규모 농업 생산 관리를 위해
-
Counting CNN model 을 기반으로 수정된 모델을 통해, 실제 환경에서 직접 수집하고 웹에서 다운로드한 데이터로 돼지 수를 예측
-
373 image를 사용한 supervised learning, image당 평균 돼지 수는 약 15마리로 각 객체의 라벨링은 어렵지 않음.
–> MAE = 2.78 : 이전 crowd counting 연구와 비슷
-
그러나 일반적 육계 모니터링은 한 이미지에 최소 수백마리로, 일부 육계는 구분할 수 없음
- 이러한 육계 이미지에 라벨링된 데이터 세트를 구축하는것은 사실상 불가능
도메인은 다르지만, crowd counting과 broiler counting은 유사한 작업이다.
도메인은 다르지만, 같은 작업을 할 때 전이 학습인 domain adaptation은 source 도메인(잘 훈련되고 라벨링된 많은 데이터 셋이 있는)을 target domain(라벨링이 잘 안된 데이터셋이 있는)으로 적용할 수 있기 때문에 유용하다.
- DANN(Domain-Adversarial Training of Neural Networks)
- reversal gradient layer , domain discriminator 추가
- DANN-based domain adaptation은 plant organ 에 적용될 수 있다. –> 육계 counting에도 적용될 수 있지않을까?
broiler(를 포함한 농업분야에서)는 라벨링된 데이터가 부족한 것이 가장 중요한 문제
broiler 밀도 기반 지도(Density map based broiler)은 broiler 수 뿐만 아니라 flock distribution(무리 분포) 추정이 가능한데, 이는 성장 행동과 사육환경의 상관관계와 관련이 크기때문에 유용하다.
따라서 DANN 기반 domain adaptation을 사용하여, Density map based broiler를 추정하고 broiler counting을 목표로 연구한다.
domain간(source domain과 target domain)의 이질적인 object를 해결하기위해 negative-patch data augmentation strategy를 사용한다.
negative-patch data augmentation strategy : source image의 임의 영역을 target image의 background로 대체 –> target domain의 distribution area 를 영역을 의도적으로 생성
- 이 방법은 weakly-supervised support로 background information을 공유함으로써 추가 annotation cost없이 가능하다.
2. Materials and methods
2.1. 밀도 맵 기반 카운팅
밀도 맵은 특정 영역의 개체 분포를 보여주는 시각화
$F_{i}(p) = \sum_{p\in P_{i}}N(p;\mu, \sigma^2 I_{2 \times 2})$
제공된 점을 기준으로 밀도 함수를 커널링하여 2차원 확률 밀도 함수로 생성 가능.
- F: 밀도 함수
- p : 이미지에 있는 각 객체의 주석이 달린 2D 픽셀 포인트
- $N(p;\mu, \sigma^2 I_{2 \times 2})$ : 점 m의 평균을 사용하여 p에서 평가된 정규화된 2D 가우스 커널
- i : i번째 이미지
$C_{i} = F_{i}(p)$
여기서 $C_{i}$는 밀도 맵의 픽셀 값과 i번째 이미지의 총 개체 수의 합
CNNs는 2D필터를 사용하여 입력 이미지의 공간 의존성 관련 객체 분포(spatial dependency-related object distribution)를 성공적으로 capture.
따라서 density map을 생성하는데 훈련시키며, 원근 왜곡을 포함한 다양한 scene에서 객체 분포 특징을 추출하는데 탁월한 성능을 보여 crowd counting에 CNN 기반 접근 방식이 제안됐다.
end-to-end 훈련기반 네트워크 아키텍쳐인 CSRNet이 backbone으로 사용됐다.
CSRNet은 다른 최신 모델에 비해, 아키텍쳐가 단순하고 훈련가능한 파라미터가 상대적으로 적으며 인코더와 디코더 구조가 명확하기때문에 DANN의 adversarial training method 적용이 쉽다.
네트워크 구성
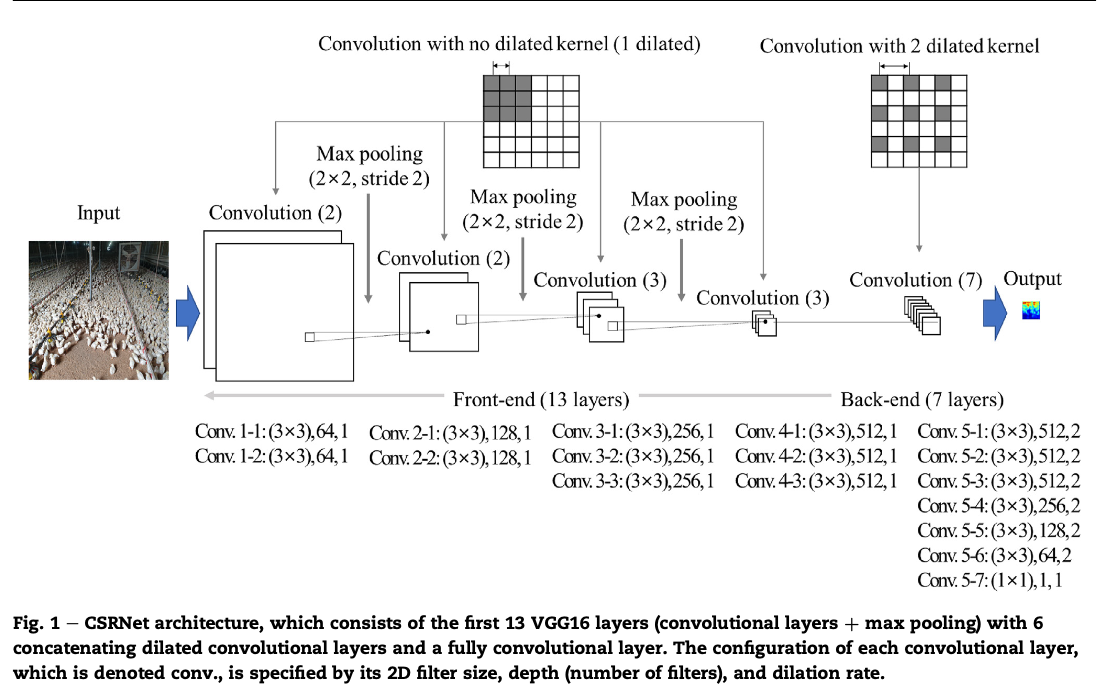
Front-end
- 13 VGG-16 layer
- same kernel size (3 x 3) with depth of 64, 128, 256, 512
- Max pooling (2x2, stride 2)
Back-end
- 7 pure convolutional layers
- 드물게 dilated kernel(확장된 커널)을 가진다.
- dilated kernel은 filter size를 dilated stride로 확대된다.
$y(m,n) = \sum_{i,j \in I}x(m + r \times i, n + r \times j)w(i,j)$
$y(m,n)$은 입력 $x(m,n)$과 필터 $w(i,j)$ 의 dilated convolution form이다.
$r$ 은 dilation rate이다.
-> pooling effect with out spatial resolution reductiokn during the convolution process
-> significant performance improvement for feature extraction
2.2 Domain adversarial neural networks(DANN)
DANN은 신경망 기반으로 간단한 수정만으로 쉽게 구현할 수 있으며, 특정 작업을 작업 도메인에 맞게 독립적으로 수정할 수 있는 것이 특징이다.
DANN은 일반적인 피드포워드 아키텍쳐에 특징 추출기와 분류기를 포함한 도메인 판별기가 추가된 복합 구성이다.
분류기는 특징 추출기의 출력 벡터를 사용하여 소스 도메인에서 샘플의 클래스 레이블을 예측하고, 레이블이 지정된 데이터로 학습한다.
도메인 판별기 역시 특징 추출기의 마지막 레이어에서 표현 벡터를 가져오지만, 전체 데이터(소스 도메인과 타깃 도메인)를 대상으로 학습하고 클래스 라벨이 아닌 샘플의 출처가 소스 도메인인지 타깃 도메인인지 판별한다.
DANN main idea
훈련 단계에서 라벨 예측 손실($Ly$)을 최소화, 도메인 판별 손실($Ld$)을 최대화하여 deep feature mapping을 위한 파라미터를 최적화.
adversarial training 입력의 클래스 레이블을 정확하게 판별하고, 입력의 출처를 무차별적으로 판별할 수 있는 특징을 도메인에서 독립적으로 표현 할 수 있다
비차별성은 소스 도메인과 타깃 도메인에 대한 특징 분포의 불일치가 최소화되어 소스 도메인 데이터에서 학습한 모델이라도 타깃 도메인 데이터 분포에서도 잘 작동할 수 있다는 것을 의미한다.
Adversarial training을 구현하기 위해 DANN은 특징 추출기와 도메인 판별기 사이에 역전파 단계에서만 작동하는 그라데이션 반전 레이어를 사용했다.
이 단일 레이어의 간단한 기능은 그라디언트 방향을 반대로 변경하는 것으로, 매개변수 Ld를 업데이트한다.
DANN 아키텍쳐는 쉽게 이용될 수 있지만, 이는 target domain의 특정 feature distribution을 명확히 설명할 수 없다는 단점이 있다.
이 문제는 Negative-patch data augmentation로 해결 할 수 있다.
2.3 Negative-patch data augmentation
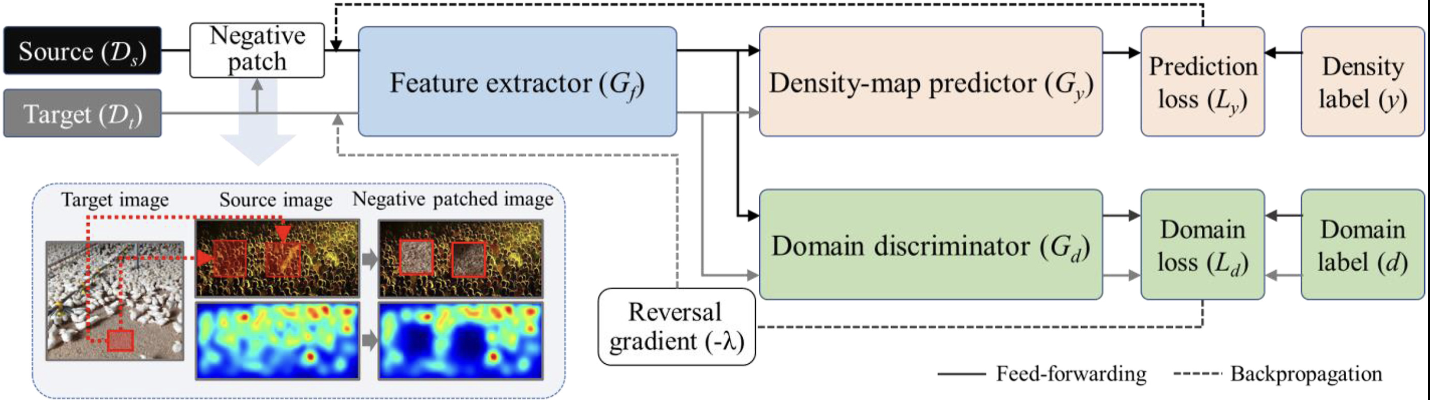
위 Fig는 위 방법이 앞서 말한 DANN을 통해 모델을 훈련하는 것이다.
(농업과 같이) 데이터 세트에 대한 레이블이 지정된 데이터가 부족하거나 없는 경우에도 밀도맵 추정을 위한 모델을 효율적으로 훈련할 수 있지만, 대상 도메인에 대한 어떤 단서도 없이 밀도 맵 추정을 한다.
이러한 한계로 인해 소스 도메인의 feature distribution이 target domain의 부적절한 공간에 mapping돼 domain adaptation 실패된다.
특히, 이질적인 도메인간에는 target domain의 feature distribution과 source domain의 feature distribution이 현저히 달라 성능 저하가 더 심해진다.
이러한 문제를 해결하기 위해 Negative-patch data augmentation이 제안된다.
Negative patch data augmentation main idea
augment source data by containing clues of target domain, background not subject to density estimation
NP의 main idea는 source data를 target domain, background의 단서를 포함하여 augment하는 것이다.
육계 무리 scene에는 사람 crowd scene에서 찾아보기 힘든 배경이 있다. 이 배경은 밀도 0을 가진다.
밀도 0이란 not annotated, have 0 value
이러한 target의 밀도 0 background를 source image로 sharing하면, model이 feature에 집중하여 훈련되는 것을 유도한다.
이러한 방법은 해당 영역의 annotation을 삭제하는 등의 추가 작업 없이도 이질적인 두 도메인 간의 domain adaptation을 할 수 있다.
NP는 background image에서 무작위로 잘라냈기 때문에, 다양한 scene과 scale이 있고, doamin adaptation을 위해 source image에 무작위로 augment했다.
NP region이 너무 크면 밀도 추정을 위한 feature이 손실될 수 있고, NP region이 너무 작으면 효과과 작을 수 있기 때문에 NP 크기를 결정하는 것이 중요하다.
NP에는 두가지 유형이 있는데 NP-p와 NP-f 이다.
- NP-p는 source image에서 밀도가 0에 가까운 영역을 대체했다.
- NP-p는 재한적이지만 배경간 교채로 인한 진실의 변화가 없기때문에 NP-f보다 효율적이다.
- NP-f는 댜앙한 배경 장면을 생성할 수 있지만 시간이 오래 걸린다.

3.Experiment and implementation
3.1 Data configuration and model training
사육 용량 : 3만 마리
고해상도 이미지(4032 x 3024) : 78
원본 이미지 : 420 (육계 데이터 샘플 375 + 네거티브 패치 증강에 사용된 배경이미지 45)
육계 데이터 샘플 : 375 - train(300), validation(38), test(37)
- Target domain data

Fig4. target image collection(left), representative scenes of broiler flock with high stocking density(right)

Fig5. 수작업으로 표기된 육계 머리 위치를 기반으로 가우시안 커널링을 통해 생성, 정확한 머리 위치 표시를 위해 이미지를 원본 이미지의 4배까지 확대한 후 주석을 달았고, 보이지 않거나 흐릿한 육계는 제외.
- Source domain data
241,667명의 인물이 주석처리된 대규모 혼잡 장면(상하이테크 파트)
-
라벨이 지정된 source domain 이미지 300개 + 라벨이 지정되지 않은 target domain 이미지 300개를 통해 training stage에서 model 훈련(파라미터 업데이트)
- 총 600개의 이미지를 사용하여 domain classifier를 훈련하고, 레이블이 지정되어있는 소스 이미지를 사용하여 density predictor를 훈련 및 실측 데이터와 유사한 density map 생성
- CSRNet(pipeline backbone)은 다양한 input size를 지원하므로, batch size는 1로 설정
- density prediction loss : MSE domain discrimination loss : cross-entropy
- using Adam optimiser
- parameter Learning rate : 1e-6 Epoch : 300 validation set was calculated in every epoch
3.2 Performance evaluation
- Baseline(DA 미적용)
- 지도학습
- 육계 데이터 세트의 38개 labelled data로 구성된 validation set을 19개와 18개로 나누어 train과 validation을 진행
-
DANN
-
DANN + NP-p
- DANN + NP-f
evaliation metric
MAE, MRAE, $R^2$
density map quality - using standard method:PSNR
Table 1. People crowd datasets used as source domain.
| Datasets | Number of images | Average count per image | Reference |
|---|---|---|---|
| SanghaiTech Part A | 482 | 501 | Zhang et al. (2016) |
| SanghaiTech Part B | 716 | 124 | |
| UCF-CC-50 | 50 | 1279 | Idrees et al. (2013) |
| UCF-QNRF | 1535 | 815 | Idrees et al. (2018) |
| JHU-CROWD | 4372 | 346 | Sindagi et al. (2020) |
peple crowd dataset 비교
4. Results and discussion
4.1 Model training
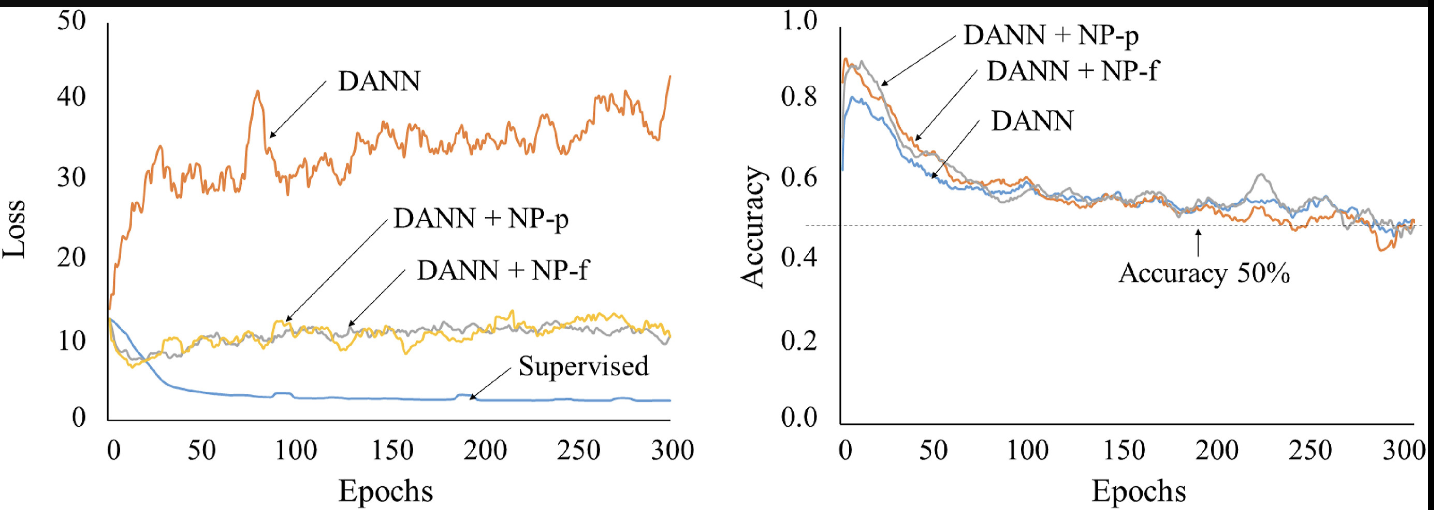
Fig. 6. Density prediction losses (left) and accuracies of domain discriminator (right) during model training.
[Loss graph]
SL은 Epochs 50이전에 급격히 감소하고 서서히 포화되는 반면, DANN 기법은 증가하는 것을 관찰할 수 있다.
DANN 손실 곡선은 처음부터 급격한 증가를 보였으며, 해당 논문에서 제안된 NP 전략은 DANN에 적용했을 때 손실 증가를 억제할 수 있었다.
이는 NP가 source domain 과 target domain 간의 feature gap을 줄이고 DANN 진행 중 domain-invariant features 추출을 돕는 것을 나타낼 수 있다.
[Accuracy graph]
값이 0.5일 때 domain classifier 가 두 domain 간 adversarial learning이 잘 수행돼 source image의 density map을 예측하고, source domain과 target domain 의 구분을 방해하도록 모델을 학습시켰음을 보인다.
4.2 Density map estimation of broiler flock
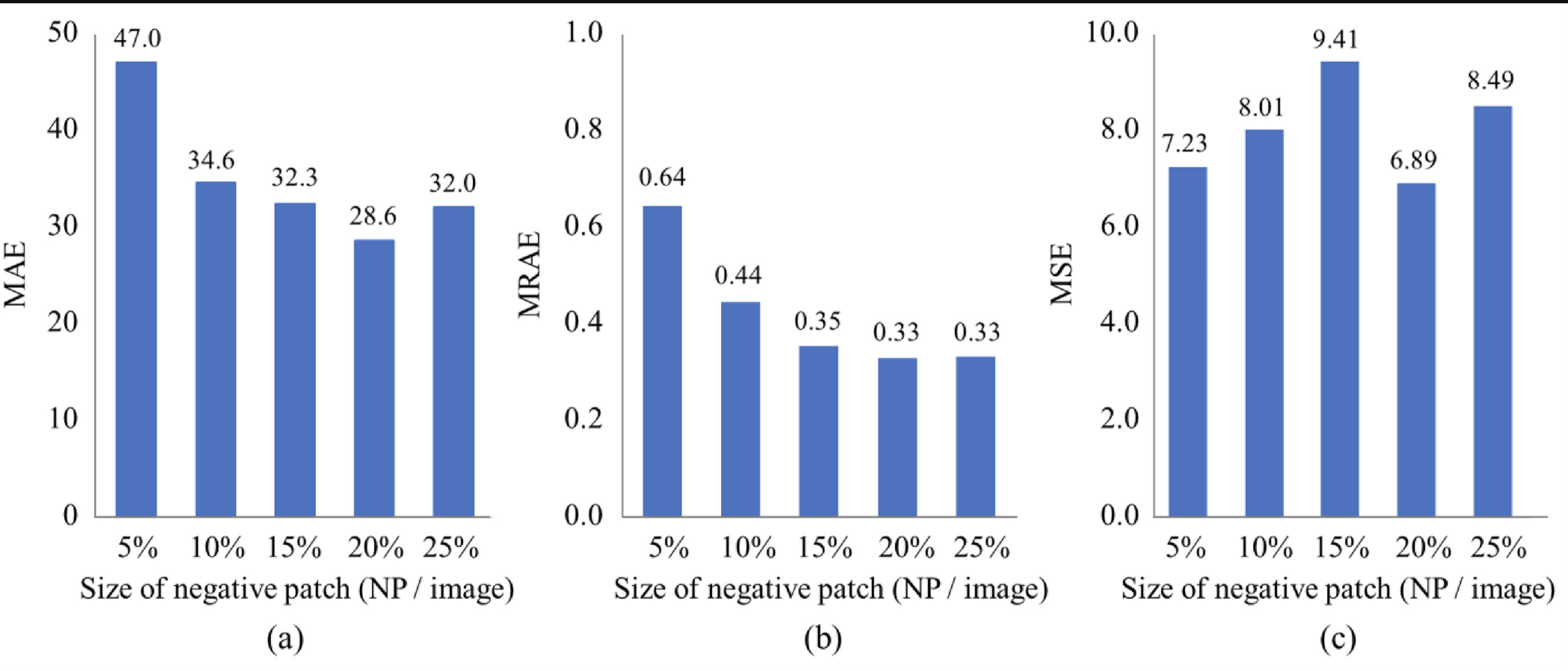
Performance of the broiler density map estimation by NP size. The comparisons were represented by using (a) MAE, (b) MRAE, and (c) MSE metrics.
NP size에 대한 estimation을 봤을 때, NP 20% 일 때 MAE, MARE가 가장 작았다. MSE는 앞선 두 지표와 비슷한 패턴을 보이지 않지만 마찬가지로 20%에서 가장 작은 것을 볼 수 있다.
모든 지표에서 20% NP size가 가장 좋은 성능을 보였기때문에 다른 시험에서도 20% NP를 수행했다.

Fig8 Estimated density maps using various methods. The results of 10 sets are expressed in 10 columns, and each result set is composed of 7 rows comprising images depicting the test image, ground truth, the results obtained via 5 methods: Baseline, SL, DANN, DANN + NP-p, and DANN + NP-f. The number at the bottom right of each image indicates the number of broiler counts.
오른쪽 아래의 숫자는 추정된 육계 수의 측정값과 예측값을 나타낸다.
SL : 소규모 레이블이 지정된 데이터 세트를 사용하기때문에 쉡게 과적합되며 밀도 맵 품질이 낮다.
DANN : 육계 수에 따라 성능에 차이가 있다.
DANN의 9번 10번 샘플을 볼때, background에 높은 밀도를 나타내는 오류가 발생한다.
이러한 에러는 이질적인 도메인때문에 일어나는데, 이는 DANN이 사람머리와 톱밥을 구분하지 않고 소스 도메인 데이터 세트에 맞게 모델을 학습시켰음을 나타낸다.
반면 NP 방법을 사용한 DANN은 SL과 DANN 보다 높은 품질의 밀도 맵을 생성할 수 있다.
또한 NP는 이미지에서 육계 수를 예측하는 DANN의 정확도를 높이는 데 기여했다.
4.3 Performances comparison of broiler counting
Table 2. Comparison of the broiler flock density prediction by the learning method.
| Method | MAE | MRAE | MSE | PSNR (dB) |
|---|---|---|---|---|
| Baseline | 142.30 | 5.77 | 120.29 | 4.88 |
| SL | 64.89 | 0.26 | 140.96 | 5.83 |
| DANN | 148.28 | 4.73 | 143.03 | 5.29 |
| DANN + NP-p | 80.11 | 0.70 | 112.94 | 5.12 |
| DANN + NP-f | 55.36 | 0.36 | 113.50 | 5.67 |
MAE : 측정된 육계수와 예측 육계수의 절대적인 차이
MRAE : 측정된 육계수에 대한 상대적인 MAE
MSE : 모델 학습 시 밀도 예측 손실로 사용되며, 밀도 맵의 공간 오차 한계를 평균화하여 계산
MAE를에서 DANN이 제일 높은 값을 보였지만, DANN에 NP를 적용한 값은 55.36까지 떨어졌다.
특히, DANN + NP-f의 경우 SL의 보다 낮은 MAE를 보이며 가장 좋은 점수를 보였는데 이는 DANN의 MAE의 37% 수준이다.
또한 NP-f DANN의 MRAE를 90%까지 줄일 수 있다.
MSE는 밀도 맵 생성의 정확도와 관련이 있는데, SL과 DANN보다 DANN + NP 방식에서 낮은 값을 보였다.
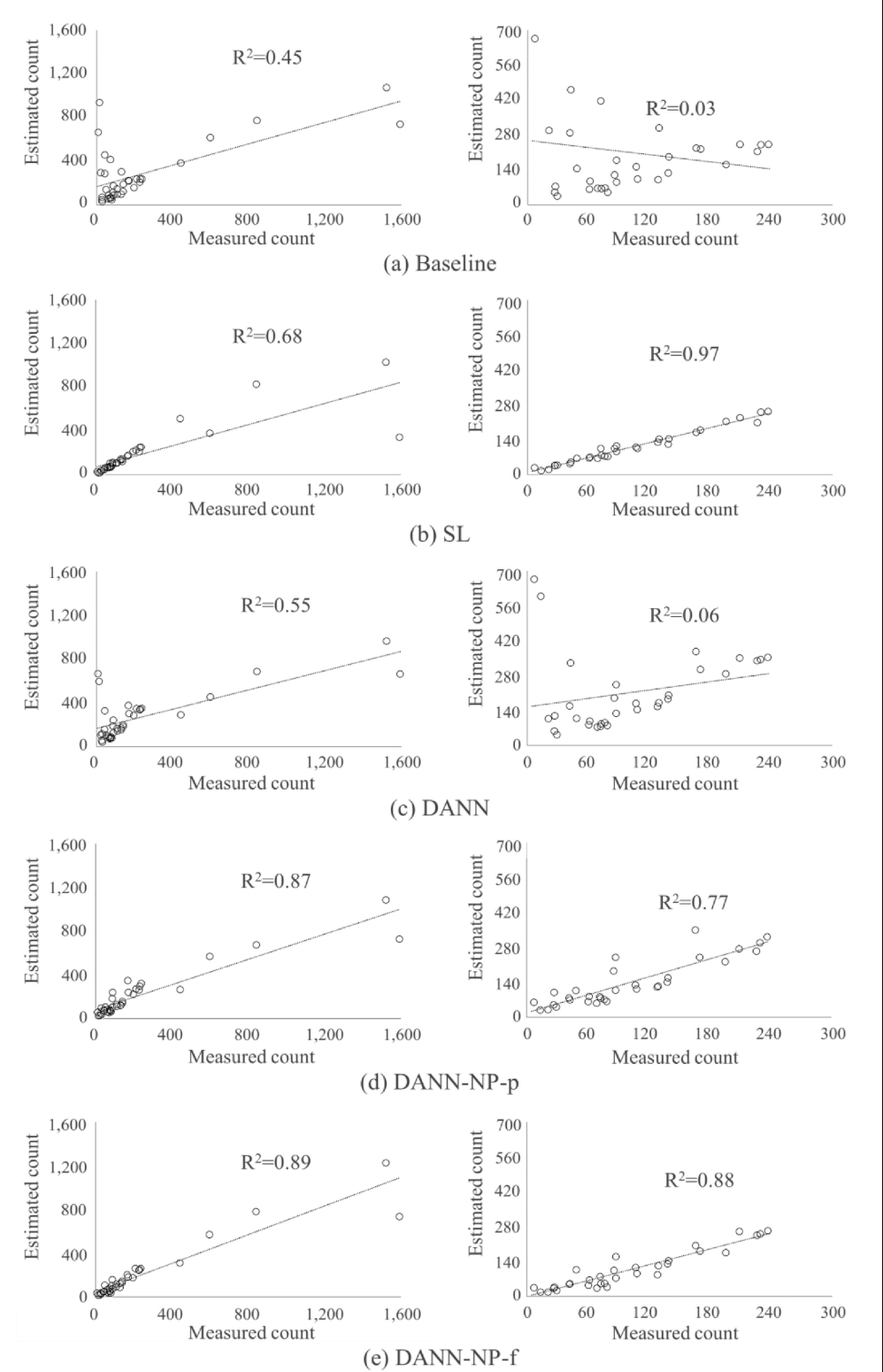
Fig. 9. Relationships between estimated and measured counts in broiler flock images. Linear regressions were represented using the entire test set (left column), and excluding the top 5 broiler count samples from the test set (right column).
DANN + NP 방법을 통해 얻은 예측된 육계 수는 실측 데이터에서 측정된 실제 육계 수와 좋은 관계를 보였다.
DANN +NP 의 선형 상관관계는 테스트 세트의 37개 샘플 모두에서 약 0.87-0.89의 범위 R2를 보였으며, R2 값은 다른 방법의 128-198%에 달했다.
대부분의 이미지가 300개 미만이므로 그림의 오른쪽 열에 표시된 것처럼 육계 수가 가장 많은 상위 5개 샘플을 제외한 32개의 테스트 이미지를 사용하여 선형 회귀를 다시 수행했다.
그 결과, 모든 테스트 이미지를 사용했을 때와 동일하게 DANN + NP-f의 R2가 계산된 반면, DANN + NP-p의 R2는 0.77로 감소했다.
SL 방법은 0.97의 R2로 육계 수를 예측할 수 있어 가장 높은 성능을 보였으며, DANN의 경우 0.06으로 선형성이 거의 없는 것으로 나타나 가장 낮은 R2를 나타냈다.
이러한 결과는 제안된 NP 전략이 사람 수 세기에 대한 지식을 육계 수 세기로 옮기기 위한 DANN 기반 도메인 적응을 성공적으로 지원할 수 있음을 보여준다.
연구에서 사용한 네 가지 도메인 적응 방법 모두에서 NP 접근법이 유의미한 우위를 보였으며, 이는 제안한 방법이 다양한 DA 방법에 공통적으로 적용될 수 있는 잠재력을 가지고 있음을 보인다.
5. Conclusion
Summary
- 본 연구에서는 이종 도메인 간의 도메인 적응 성능을 향상시키기 위해 NP 데이터 증강 전략을 제안
- 육계 무리 밀도 추정에 대한 DANN에 NP 전략을 적용하여 검정을 실시했다.
- 농업 분야에서 라벨링된 데이터의 부족을 극복하기 위해 라벨링된 이미지로 구성된 사람들의 군중 데이터 세트를 소스 도메인 데이터 세트로 사용하고 라벨링되지 않은 이미지로 구성된 육계 데이터 세트를 타겟 도메인 데이터 세트로 사용
- 딥러닝 모델과 도메인 적응 방법을 위한 백본 아키텍처로 CSRNet과 DANN이 각각 사용
- 5가지 학습방법을 이용하여 밀도추정을 바탕으로 영상 내 육계의 수를 계수하였고, 육계 데이터셋의 테스트 영상을 이용하여 방법의 성능을 비교
- 밀도 맵 추정에서는 DANN에 NP 데이터 증강을 추가하면 도메인 불변 특성을 학습하여 객체 분포에 맞게 소스 도메인과 타겟 도메인 모두에서 밀도 맵을 정확하게 예측한 반면, DANN만으로 모델을 학습시켰을 때 일부 샘플에서는 밀도 맵이 잘못 예측.
- 다양한 피플 크라우드 데이터 세트를 적용하여 실험을 통해 일반화된 성능을 입증
- 특히 NP-f는 소스 영상에서 배경뿐만 아니라 사람들이 모여 있는 영역을 공유해 배경을 담은 다양한 데이터셋을 생성하여 최상의 성능
- NP-p는 모델 훈련 시 지상진도의 재생과 자동적인 구현이 필요하지 않아 실용적인 측면에서 장점
Limitation
-
annotation inaccuracies : validation set과 test set의 broiler congested regions에서의 annotation 부정확성, 성능 저하
-
target domain set을 source domain set 수준까지는 높이지 못함